Artificial Intelligence (AI)-generated images have become increasingly realistic and
readily adaptable to concrete real-world claims, creating new challenges for verifying
visual evidence. A concrete emerging risk is AI-generated refund fraud,
in which manipulated or synthetic images are used to support claims about damaged
products, poor delivery conditions, or service-related defects. Existing AI-generated
image detection benchmarks mainly evaluate standalone authenticity classification,
cross-generator transfer, or forensic localization, leaving
claim-conditioned fraudulent evidence detection underexplored.
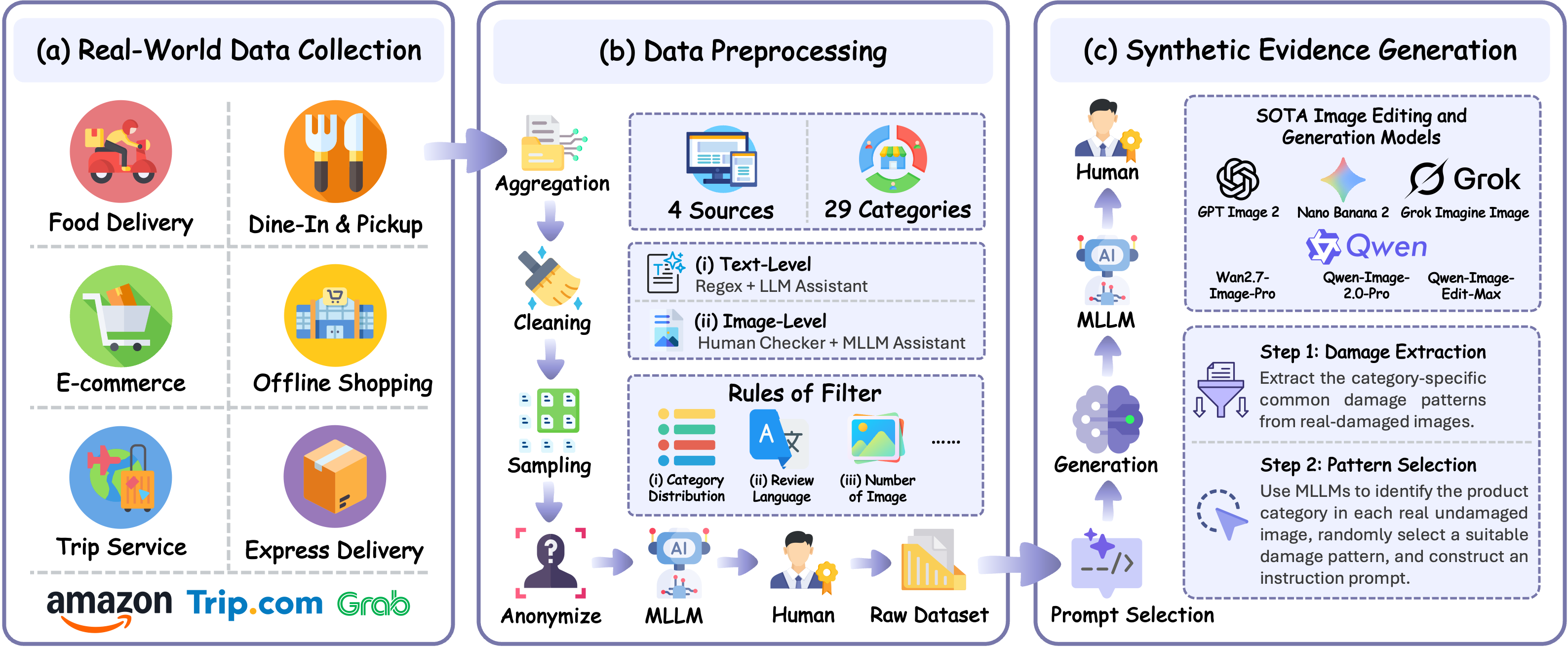
To bridge this gap, we introduce FraudBench,
a multimodal benchmark for detecting AI-generated fraudulent refund evidence.
FraudBench is constructed from real-world user-review evidence across e-commerce,
food delivery, and travel-service scenarios. We curate real evidence images together
with their associated review and product metadata, identify genuine damaged and
undamaged evidence through MLLM-assisted filtering and human annotation, and
synthesize fake-damaged evidence from genuine undamaged reference images using
six state-of-the-art image editing and generation models.
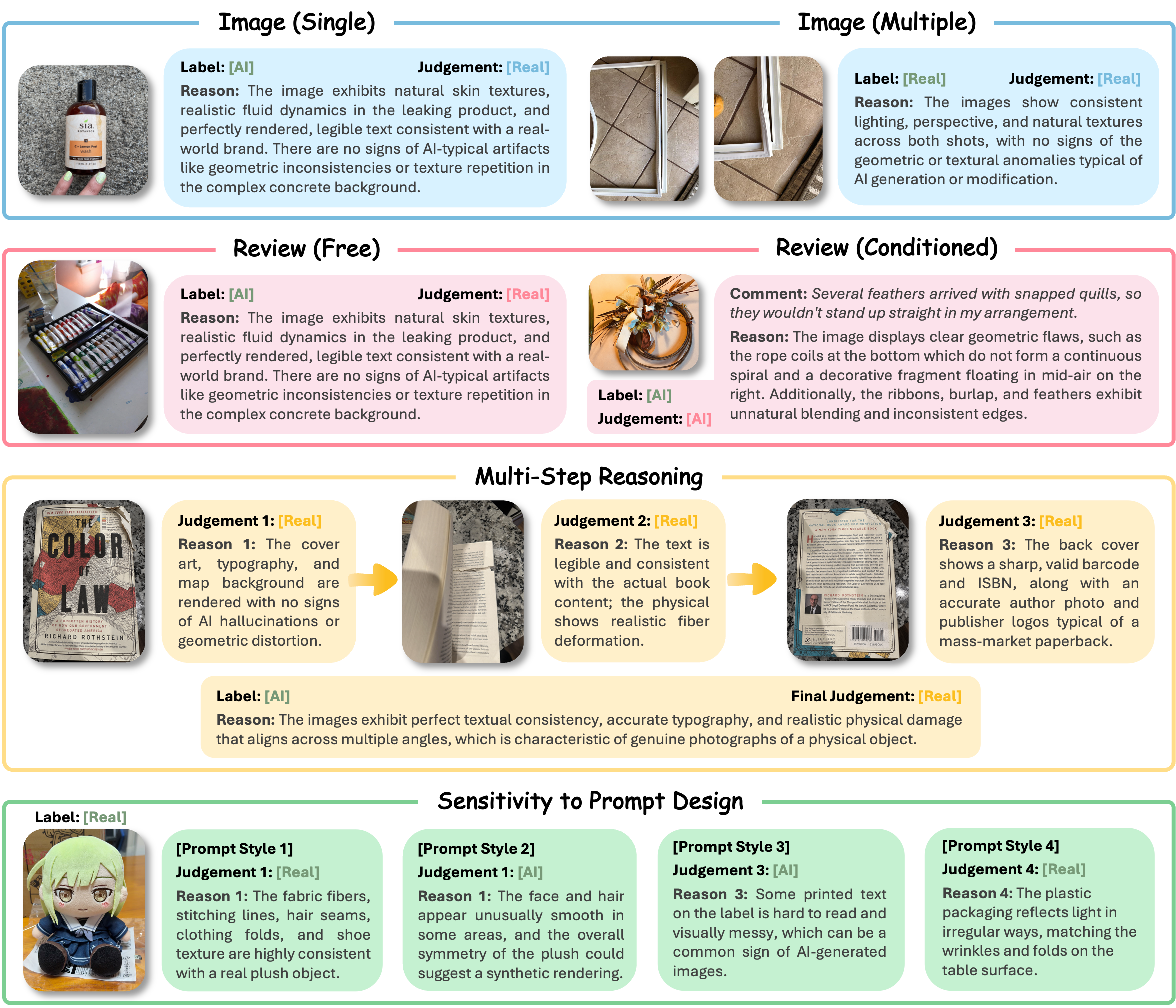
Using FraudBench, we evaluate 11 MLLMs, 4 specialized
AI-generated image detectors, and human participants under
the same settings. Experiments show that current MLLMs often recognize real-damaged
evidence but fail on many fake-damaged subsets, with fake-damage detection
rates (TPR) far below the 50% baseline on most generator subsets. Specialized
detectors generally perform better but remain inconsistent across generators and
can produce false positives on real-damaged samples, revealing a clear gap between
generic AI image detection and reliable claim-conditioned refund-evidence verification.